성능을 높히는 데이터 지향 설계 (Data Oriented Design, DOD)
이 글은 제 개인적인 공부를 위해 작성한 글입니다.
틀린 내용이 있을 수 있고, 피드백은 환영합니다.
개요
많은 개발자에게 익숙한 객체 지향 설계(OOP)와 특히 게임 개발과 같이 대규모 데이터 처리에서 성능 향상을 가져오는 데이터 지향 설계(DOD)에 대해 알아보자
객체 지향 설계 (Object Oriented Design, OOD)
객체 지향 설계는 현실 세계를 바라보는 방식과 유사하게 프로그래밍하는 접근법이다. 연관 있는 데이터와 기능을 하나의 객체로 묶어 관리한다. 마치 자동차라는 객체가 있다면, 그 안에 색상, 속도라는 데이터와 달린다(), 멈춘다()라는 기능이 함께 들어가 있다.
아래는 OOP 방식의 간단한 플레이어 클래스 예시이다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class Player
{
public:
FVector position;
float health;
float mana;
void TakeDamage(float damage)
{
health -= damage;
}
void Move(FVector direction)
{
position += direction;
}
};
Player라는 객체 안에 위치, 체력, 마나 데이터와 피해를 입고 움직이는 기능이 포함되어 있어 코드가 직관적이고 이해하기 쉽다.
1
2
3
4
5
6
7
8
9
10
TArray<Player> players;
void UpdatePlayersPosition(TArray<Player>& players, FVector direction)
{
for (Player& player : players)
{
player.Move(direction);
}
}
하지만 위의 플레이어의 위치를 갱신하는 함수를 보면 players 배열을 순회하며 각 플레이어 객체의 Move() 함수를 호출한다. 이 과정에서 각 플레이어 객체의 위치 데이터가 메모리 상에 흩어져 있을 수 있다. 따라서 캐시 미스가 발생할 확률이 높아지고, 이는 성능 저하로 이어질 수 있다.
데이터 지향 설계 (Data Oriented Design, DOD)
데이터 지향 설계는 OOP와는 정반대의 질문에서 출발한다. 이 객체가 무엇인가?가 아니라, 어떤 데이터를 어떻게 처리해야 가장 빠른가에 집중한다.
데이터 지향 설계의 핵심 원칙은 다음과 같다.
- 데이터 구조화 : 데이터를 구조화하고 관련 있는 데이터를 물리적으로 서로 가까운 위치에 저장하여 메모리 접근 속도를 높이고 캐시 효율성을 개선한다.
- 데이터 변환 : 프로그램을 데이터 변환 단계로 분해하여 각 단계에서 데이터를 처리하는 데 필요한 최소한의 정보만 사용하도록 한다.
- 메모리 접근 최적화 : 데이터를 연속적인 메모리 블록에 저장하여 캐시 지역성을 개선하고, 메모리 접근을 최소화하여, 메모리에 효율적으로 접근하는 알고리즘을 사용한다.
- 병렬성 고려 : 데이터를 독립적으로 처리할 수 있는 작은 단위로 분할하여 병렬 처리를 용이하게 하고, 다중 코어 및 다중 스레드 프로세서의 성능을 최대한 활용한다.
데이터 지향 설계의 장점은 성능 최적화와 주로 관련 있다. 캐시 효율성을 높여 연산 속도를 빠르게 하고, 병렬 처리를 통해 다중 코어 및 다중 스레드 프로세서의 성능을 극대화할 수 있다. 이러한 이유로 데이터 지향 설계는 수 많은 오브젝트가 존재하는 게임 개발에서 선호된다고 한다.
아래는 DOD 방식의 간단한 플레이어 데이터 구조 예시이다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
struct CharacterData
{
TArray<FVector> positions;
TArray<float> healths;
TArray<float> manas;
};
class CharacterSystem
{
public:
void UpdatePositions(CharacterData& data, FVector direction)
{
for (FVector& pos : data.positions)
{
pos += direction;
}
}
};
모든 캐릭터의 위치 데이터는 하나의 위치 배열에, 체력 데이터는 하나의 체력 배열에 모여있다. 하나의 위치 데이터를 갱신하기 위해 CPU는 연속된 메모리에 있는 위치 데이터 묶음을 캐시에 한 번에 불러온다. 다음 위치 데이터를 처리할 차례가 되면, 해당 데이터는 이미 캐시 메모리에 들어와 있을 확률이 높으므로, 캐시 히트가 높아질 수 밖에 없다.
그렇다면 왜 아직도 객체 지향 설계를 사용할까?
성능이 개발의 모든 것을 결정하지 않기 때문이라고 생각한다. OOP는 사람의 사고 방식과 닮았기 때문에 더 쉽게 이해할 수 있고 유지보수가 쉽다.
하지만 DOD는 데이터를 처리하기 좋은 형태로 정렬하는 데에 집중하므로, 우리 입장에서는 전체적인 흐름을 파악하기 더 어려울 수 있다. 어떤 설계 방식이 무조건 더 좋다기 보다는, 상황에 맞게 적절히 사용하는 것이 중요하다고 생각된다.
게임의 전체적인 뼈대와 캐릭터, UI와 같은 복잡한 상호작용 시스템은 OOP로 구축하고, 수천 개의 총알처럼 성능이 중요한 부분에만 DOD를 적용하여 최적화하는 것이 이상적인 접근법이라고 생각된다.
웹 개발에서는 나노초 정도를 다루는 문제가 거의 없고, 성능보다는 가독성과 유지보수성을 중요시하기에 OOP가 더 널리 사용되는 듯하다.
메모리 캐싱과 명령어의 레이턴시
https://tsyang.tistory.com/68에서 잘 설명되어 있다.
https://www.agner.org/optimize/instruction_tables.pdf
위 문서를 보면 제곱근을 구하는 명령어 SQRT의 레이턴시는 약 15 사이클, 삼각함수의 경우에는 100~300 사이클을 왔다갔다 한다고 한다.
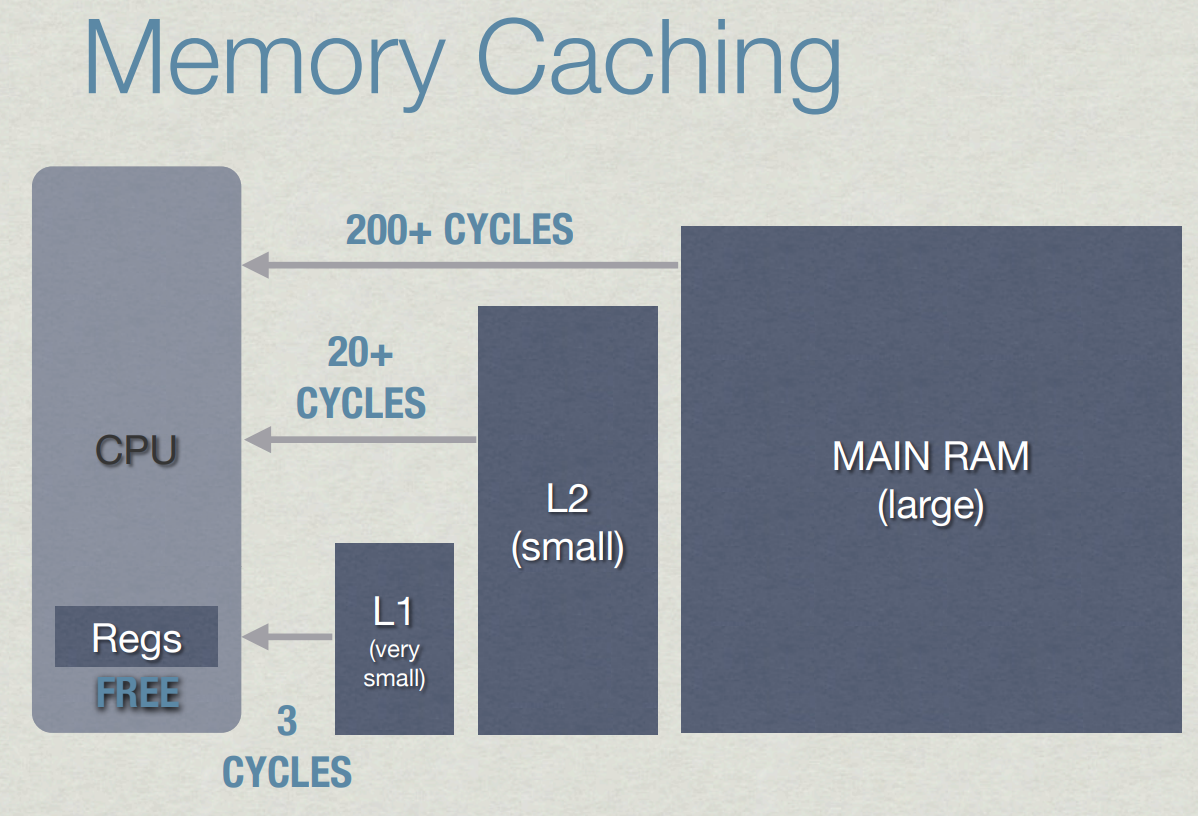
메모리에 접근하는 속도는 하드웨어마다 다르겠지만 L1 캐시는 3 사이클, L2~3 캐시는 10~30 사이클, 메모리는 200 사이클+가 필요하다고 해보자
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class APlayer : public AActor
{
FVector Velocity = FVector::ZeroVector;
float Foo = 0.0f;
virtual void Tick(float DeltaTime) override
{
Super::Tick(DeltaTime);
UpdateFoo(DeltaTime);
}
void UpdateFoo(float DeltaTime)
{
const float Speed = Velocity.Size2D();
Foo += Speed * DeltaTime;
}
};
먼저 FVector::Size2D()는 내부적으로 sqrt(XX + YY)를 계산한다.
1
2
3
4
5
template<typename T>
FORCEINLINE T TVector<T>::Size2D() const
{
return FMath::Sqrt(X*X + Y*Y);
}
위와 같은 간단한 플레이어 클래스가 있고, UpdateFoo() 함수를 보면 제곱근을 구하는 Size2D() (= Sqrt)가 성능에서 가장 중요한 부분이라고 생각할 수 있다.
UpdateFoo()에서 Sqrt와 곱셈 덧셈 연산을 다 합쳐도 40 사이클 정도의 레이턴시가 발생할 것이다.
하지만 Velocity라는 변수가 메모리 어디에 위치하는지에 따라, 즉 캐시 히트가 발생하는지에 여부에 따라 성능이 크게 달라질 수 있다.
만약 Velocity를 가져오는데 메모리 접근이 필요하다면 200 사이클+가 추가로 필요하다. Foo 변수를 읽어와 값을 쓰는데도 200 사이클+가 추가로 필요하다.
그러니까 수학 연산하는데 40 사이클 정도 필요한데, 메모리에서 값을 읽어와 쓰는 데에 400 사이클이나 필요할 수 있다. 즉, 수학 연산하는데 드는 시간은 전체 계산 시간의 10% 밖에 안되는 셈이다.
또한 일반적으로 메모리와 L1, L2 캐시에서 값을 불러오는 단위인 캐시 라인은 64바이트인데, FVector는 12바이트, float는 4바이트이다. Velocity와 Foo는 각각 52, 60 바이트를 낭비하는 셈이니 꽉꽉 채워 사용하면 효율적이게 된다.
이를 데이터 지향 설계로 수정해보면 아래와 같이 될 것이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
struct FPlayerDataCollection
{
TArray<FVector> AllVelocities;
TArray<float> AllFoos;
};
class PlayerSystem
{
public:
static void UpdateAllFoos(FPlayerDataCollection& Data, float DeltaTime)
{
for (int32 i = 0; i < Data.AllVelocities.Num(); ++i)
{
const float Speed = Data.AllVelocities[i].Size2D();
Data.AllFoos[i] += Speed * DeltaTime;
}
}
};
위 코드처럼 여러 개의 플레이어를 함께 업데이트해주면 어떨까?
예를 들어 32개의 플레이어가 있다면 Velocity를 이용해 Foo를 업데이트한다. 32개의 플레이어가 각각 2번씩 캐시라인을 사용하기에 다 합치면 64개의 캐시라인이 사용된다.
새로운 방법은 32개의 Velocity = 32 * 12 = 384 바이트니까 6개의 캐시라인 32개의 Foo = 32 * 4 = 128 바이트니까 2개의 캐시라인을 사용한다.
캐시라인만 봐도 기존 방법은 64 * 200 = 12800 사이클이 필요하지만, 새로운 방법은 8 * 200 = 1600 사이클이 필요하다. 8배가 차이가 난다.
참고