동적계획법 Dynamic Programming
이 글은 제 개인적인 공부를 위해 작성한 글입니다.
틀린 내용이 있을 수 있고, 피드백은 환영합니다.
개요
동적 계획법(Dynamic Programming, DP)은 복잡한 문제를 작은 문제들로 나누어 해결한 뒤, 그 결과 값을 저장해두었다가 다시 사용하는 알고리즘 기법이다.
일반적인 재귀 방식은 같은 계산을 다시 반복해야 할 때가 많아 효율성이 떨어진다.
DP는 한 번 계산한 것은 어딘가에 적어두고 다시 계산하지 않는다는 전략을 사용한다.
DP를 사용할 수 있는 두 가지 조건
중복 부분 문제 (Overlapping Subproblems)
DP는 기본적으로 문제를 나누고 그 문제의 결과 값을 재활용해서 전체 답을 구한다.
그래서 동일한 작은 문제들이 반복하여 나타나는 경우에 사용이 가능하다.
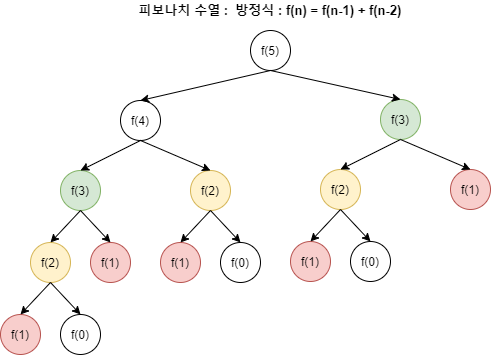
피보나치 수열에서 f(5)를 구한다고 할 때, f(3), f(2), f(1)과 같이 동일한 부분 문제가 중복된다.
최적 부분 구조 (Optimal Substructure)
부분 문제의 최적 해를 사용해 전체 문제의 최적 해를 낼 수 있는 경우를 의미한다.
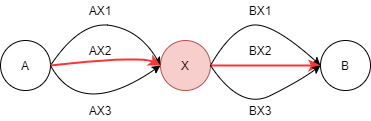
A-B의 최단 경로를 찾고자 할 때, A-X / X-B가 많은 경로 중 가장 짧은 경로라면 전체 최적 경로도 A-X-B가 정답이 된다.
이 두 가지 조건이 충족한다면, 동적 계획법을 이용하여 문제를 풀 수 있다.
접근 방식
DP로 풀 수 있는 문제인지 확인
현재 직면한 문제가 작은 문제들로 이루어진 하나의 함수로 표현될 수 있는지 판단
즉, 위에 쓴 조건들이 충족되는 문제인지를 한 번 체크
문제의 변수 파악
현재 변수에 따라 그 결과 값을 찾고 그것을 전달하여 재사용하는 것을 거친다.
가령 피보나치 수열에서는 $n$번째 숫자를 구하는 것이므로 $n$이 변수가 된다.
변수 간 관계식 만들기 (점화식)
점화식을 반복/재귀를 통해 자동으로 해결되도록 구축한다.
가령 피보나치 수열에서는 $f(n)=f(n-1)+f(n-2)$이다.
메모하기 (Memoization or Tabulation)
변수의 값에 따른 결과를 저장하고, 저장된 값을 재사용한다.
기저 상태 파악하기
가장 작은 문제의 상태를 알아야 한다.
가령 피보나치 수열에서는 $f(0)=0,\;f(1)=1$
구현하기
DP는 2가지 방식으로 구현할 수 있다.
- Bottom-Up (반복문 + Tabulation)
- Top-Down (재귀 + Memoization)
구현
Bottom-Up (반복문 + Tabulation)
가장 작은 문제부터 차례대로 답을 구해나가는 방식이다. 표를 채워나간다는 의미에서 타뷸레이션이라고 부른다.
dp[0]이 기저 상태이고 dp[n]을 목표 상태라고 하자.
dp[0]부터 시작해서 반복문을 통해 점화식으로 결과를 내서 dp[n]까지 그 값을 전이시켜 재활용하는 방식이다.
1 2 3 4 5 6 7 8 9
def fibo_tabulation(n): if n < 2: return n fib = [0, 1] for i in range(2, n + 1): fib.append(fib[i - 1] + fib[i - 2]) return fib[n]
Top-Down (재귀 + Memoization)
큰 문제를 해결하기 위해 작은 문제를 호출하는 방식이다.
계산 결과를 리스트나 배열에 담아두는 것을 메모이제이션이라고 한다.
dp[n]의 값을 찾기 위해 n에서 바로 호출을 시작하여 dp[0]의 상태까지 내려간 다음 해당 결과 값을 재귀를 통해 전이시켜 재활용하는 방식이다.
1 2 3 4 5 6 7 8
def fibo_memoization(n, memo): if n < 2: return n if memo[n] == 0: memo[n] = fibo_memoization(n - 1, memo) + fibo_memoization(n - 2, memo) return memo[n]
분할 정복(Divide and Conqure)과의 비교
DP와 분할 정복은 큰 문제를 작은 여러 개의 부분 문제로 나누어 해결하는 비슷한 방식을 가지고 있다.
하지만 부분 문제로 만드는 과정에서 중복 여부에 대한 차이점이 존재한다. DP는 부분 문제가 중복되어 해를 재사용하지만, 분할 정복은 부분 문제가 중복될 수 없다.
분할 정복 방식이 사용되는 병합 정렬을 살펴보면, 정렬 시에 부분 문제로 쪼개어지지만 중복하여 부분 문제가 발생하지 않으므로 부분 문제는 모두 독립적이다.
욕심쟁이 기법(Greedy Algorithm)과의 비교
DP는 가능한 모든 방법을 고려해야 한다는 단점이 있기에 이러한 단점을 극복하기 위해, 욕심쟁이 기법이 등장했다.
욕심쟁이 기법이 항상 최적해를 구해주지는 않지만, 최소 신장 트리와 같은 문제에서는 최적해를 구할 수 있다.
A 노드에서 B 노드로 가는 최단 경로를 구하고 싶을 때 DP와 욕심쟁이 기법을 비교해보면, DP는 모든 노드와 에지와 가중치를 감안하여 최적 해를 찾아내지만, 그리디 알고리즘은 현재 노드에서의 가장 짧은 에지를 선택할 것이다.
DP는 욕심쟁이 기법에 비해 약간 시간이 더 걸리겠지만 최적 해를 보장받을 수 있고, 욕심쟁이 기법은 항상 최적 해임을 보장받을 수 없다.
참고