[운영체제 아주 쉬운 세 가지 이야기 - Concurrency] 29. Locked Data Structures

이 글은 제 개인적인 공부를 위해 작성한 글입니다.
틀린 내용이 있을 수 있고, 피드백은 환영합니다.
개요
다른 주제로 넘어가기 전에 먼저 흔하게 사용되는 자료 구조에서 락을 사용하는 방법을 살펴보자. 자료 구조에 락을 추가하여 쓰레드가 사용할 수 있도록 만들면 그 구조는 쓰레드 안전(thread-safe)하다고 할 수 있다. 물론, 락이 어떤 방식으로 추가 되었느냐에 따라 그 자료 구조의 정확성과 성능을 좌우할 것이다. 주어진 도전은 다음과 같다.
그렇다면 특정 자료 구조가 주어졌을 떄, 어떤 방식으로 락을 추가해야 그 자료 구조가 정확하게 동작할 수 있을까? 더 나아가, 자료 구조에 락을 추가하여 여러 쓰레드가 그 자료 구조를 동시 사용이 가능하도록 하면(병행성) 고성능을 얻기 위해 무엇을 해야 할까?
모든 자료 구조를 다 다루거나 병행성이 가능하도록 하는 모든 기법을 다루기는 힘들다. 여기서는 어떤 사고 방식으로 이 주제를 접근해야 하는지를 소개하고자 한다.
병행 카운터
카운터는 가장 간단한 자료 구조 중 하나이다. 보편적으로 사용되는 구조이면서 인터페이스가 간단하다. 병행이 불가능한 카운터를 아래 그림에서 정의한다.
간단하지만 확장성이 없음

보는 바와 같이, 동기화되지 않은 카운터는 몇 줄 안되는 코드로 작성할 수 있는 평범한 자료 구조이다. 그렇다면 이 코드를 어떻게 쓰레드 안전(thread-safe)하게 만들 수 있을까? 그림 32.2에서 그 방법을 나타내었다.

이 병행이 가능한 카운터는 간단하지만 정확하게 동작한다. 사실 이 카운터는 가장 간단하고 기본적인 병행 자료 구조의 보편적인 디자인 패턴을 따른다. 자료 구조를 조작하는 루틴을 호출할 때 락을 추가하였고, 그 호출문이 리턴할 때 락이 해제되도록 하였다. 이 방식은 모니터(monitor)를 사용하여 만든 자료 구조와 유사하다 모니터 기법은 객체에 대한 메소드를 호출하고 리턴할 때 자동적으로 락을 획득하고 해제한다.
이제 제대로 동작하는 병행 자료 구조를 갖게 되었다. 그렇지만 성능이 문제다. 자료 구조가 너무 느리다면 단순히 락을 추가하는 것 이상의 무엇인가를 해야 한다. 성능 최적화가 이번 장에서 다룰 내용이다. 자료 구조가 많이 느리지 않다면 할 일을 다 했다. 간단하게 해서 되는 일을 복잡하게 처리할 필요는 없다.
먼저 이 간단한 방법의 성능을 이해하기 위해서 각 쓰레드가 특정 횟수만큼 공유 카운터를 증가시키는 벤치마크를 실행하였다. 그리고 쓰레드의 개수를 증가시켜 보았다. 아래 그림에 하나에서 네 개의 쓰레드를 사용하여 카운터를 백만 번 증가시켰을 때 총 걸린 시간을 나타내었다. 더 많은 CPU가 동작할수록 단위 시간당 총 수행량이 늘어날 것으로 기대한다.
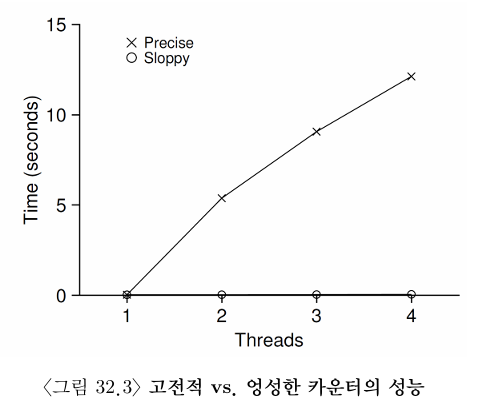
precise라고 표시된 선에서 동기화된 카운터의 확장성이 떨어지는 것을 볼 수 있다. 단일 쓰레드로 카운터를 백만 번 갱신하는 데 대략 0.03초가 걸렸다. 두 개의 쓰레드로 카운터 값을 백만 번 갱신하는 데 약 5초 이상이 걸렷다.
이상적으로는 하나의 쓰레드가 하나의 CPU에서 작업을 끝내는 것처럼 멀티프로세서에서 실행되는 쓰레드들로 빠르게 작업을 처리하고 싶을 것이다. 이와 같이 동작하는 것을 완벽한 확장성(perfect scaling)이 있다, 완벽한 확장성은 더 많은 작업을 처리하더라도 각 작업이 병렬적으로 처리되어 완료 시간이 늘어나지 않는다는 것을 말한다.
확장성 있는 카운팅
수년 동안 확장성 있는 카운터를 만들기 위해 많은 연구 활동을 하였다. 확장성 있는 카운터는 중요한 의미를 갖는다. 최근 운영체제 성능 분석 결과에 의하면 확장 가능한 카운터가 없으면 Linux의 몇몇 작업은 멀티코어 기기에서 심각한 확장성 문제를 겪을 수 있다고 한다.
개발된 여러 기법 중 하나를 소개한다. 최근에 소개된 엉성한 카운터(sloppy counter)라고 불리는 기법이다.
엉성한 카운터는 하나의 논리적 카운터로 표현되는데, CPU 코어마다 존재하는 하나의 물리적인 지역 카운터와 하나의 전역 카운터로 구성되어 있다. 어떤 기기가 네 개의 CPU를 갖고 있다면 그 시스템은 네 개의 지역 카운터와 하나의 전역 카운터를 갖고 있다. 이 카운터들 외에 지역 카운터를 위한 락들과 전역 카운터를 위한 락이 존재한다.
엉성한 카우넡의 기본 개념은 다음과 같다.
- 쓰레드는 지역 카운터를 증가시킨다.
- 이 지역 카운터는 지역 락에 의해 보호된다.
- 각 CPU는 저마다 지역 카운터를 갖기 때문에 CPU들에 분산되어 있는 쓰레드들은 지역 카운터를 경쟁 없이 갱신할 수 있다.
- 그러므로 카운터 갱신은 확장성이 있다.
쓰레드가 카운터의 값을 읽을 수 있기 때문에 전역 카운터를 최신으로 갱신해야 한다. 최신 값으로 갱신하기 위해서 지역 카운터의 값은 주기적으로 전역 카운터로 전달되는데, 이때 전역 락을 사용하여 지역 카운터의 값을 전역 카운터의 값에 더하고, 그 지역 카운터의 값은 0으로 초기화한다.
지역에서 전역으로 값을 전달하는 빈도는 정해 놓은 S(sloppiness) 값에 의해 결정된다. S의 값이 작을수록 확장성 없는 카운터처럼 동작하며, 커질수록 전역 카운터의 값은 실제 값과 차이가 있게 된다. 정확한 카운터의 값을 얻기 위해 모든 지역 락과 전역 락을 획득한 후에 계산을 하면 되지만, 확장성이 없게 된다. 이 경우에, 지역 락을 획득하는 순서를 적절히 제어하지 않으면 교착 상태가 발생한다.
그림 32.4에서 한계치를 5로 설정하였고 네 개의 CPU에 각각의 지역 카운터 L1, …, L4를 갱신하는 쓰레드들이 있다. 전역 카운터의 값(G)도 같이 나타내었는데, 만약 지역 카운터가 한계치 S에 도달하면 지역 값은 전역 카운터에 반영되고 지역 카운터의 값은 초기화된다.
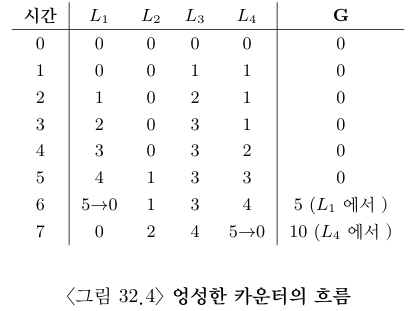
그림 32.3에서 범례에 sloppy라고 적힌 아래 선이 S 값을 1024로 했을 때 엉성한 카운터의 탁월한 성능이다. 네 개의 프로세서에서 카운터의 값을 4백만 번 갱신하는 데 걸린 시간이 하나의 프로세서에서 백만 번 갱신하는 시간에 비해 그리 크지 않다.
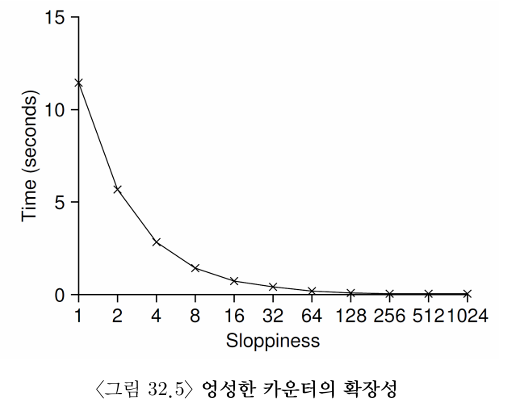
그림 32.5는 4개의 CPU에서 4개의 쓰레드가 각각 백만 번 카운터의 값을 증가하는 경우 한계치 S의 설정이 얼마나 중요한지를 보여준다. S의 값이 낮다면 성능이 낮은 대신 전역 카운터의 값이 매우 정확해진다. S의 값이 매우 크다면 성능은 탁월하겠지만 전역 카운터의 값은 CPU의 개수와 S의 곱만큼 뒤처지게 된다. 엉성한 카운터는 정확도와 성능의 균형을 조절할 수 있다.
엉성한 카운터의 대략적인 코드를 그림 32.6에 나타내었다. 더 좋은 방법은 이 기법을 사용하는 실험을 해보고 어떻게 동작하는지 자세히 이해하는 것이다.

병행 연결 리스트
이제 조금 더 복잡한 구조인 연결 리스트를 다뤄보자. 기본적인 것을 갖고 시작해 보자. 간단하게 하기 위해서, 병행 삽입 연산만 살펴보자. 검색, 삭제와 같은 연산은 독자의 몫으로 나겨 두겠다. 그림 32.7은 자료 구조의 기본이 되는 코드이다.

코드에서 볼 수 있듯이, 삽입 연산을 시작하기 전에 락을 획득하고 리턴 직전에 해제한다. 매우 드문 경우지만, malloc()이 실패할 경우에 미묘한 문제가 생길 수 있다. 그런 경우가 발생한다면 실패를 처리하기 전에 락을 해제해야 한다.
예외 처리에서는 쉽게 오류가 발생하는 것으로 알려져 있다. 최근 Linux 커널 패치에 관한 연구에 따르면 약 40%에 달하는 버그가 자주 사용되지 않는 이런 코드에서 발생된 것으로 조사되었다.
다음을 해결해 보자. 삽입 연산이 병행되어 진행되는 상황에서 실패를 하더라도 락 해제를 호출하지 않으면서 삽입과 검색이 올바르게 동작하도록 수정할 수 있을까?
답은 가능하다이다. 삽입 코드에서 임계 영역을 처리하는 부분만 락으로 감싸도록 코드 순서를 변경하고, 검색 코드의 종료는 검색과 삽입 모두 동일한 코드 패스를 사용토록 할 수 있다.
이 방법이 동작하는 이유는 검색 코드의 일부는 사실 락이 필요 없기 떄문이다. malloc() 자체가 쓰레드 안전하다면 쓰레드는 언제든지 경쟁 조건과 다른 병행성 관련 버그를 걱정하지 않으면서 검색할 수 있다. 공유 리스트 갱신 때에만 락을 획득하면 된다. 변경된 세부 내용을 이해하기 위해 그림 32.8을 보자

검색 루틴의 while 문 안에 break를 삽입하여 검색이 성공하면 바로 빠져나오게 수정한다. 이렇게 하면 검색 성공이나 실패의 경우 모두 동일한 리턴 코드를 실행한다. 이렇게 하면 코드에서 락을 획득하고 해제하는 문장 수를 줄일 수 있다. 락을 해제하지 않고 리턴하는 것과 같은 버그 발생 여지가 줄어든다.
확장성 있는 연결 리스트
병행이 가능한 연결 리스트를 갖게 되었지만 확장성이 좋지 않다는 문제가 있다. 병행성을 개선하는 방법 중 하나로 hand-over-hand locking (또는 lock coupling)이라는 기법을 개발했다.
개념은 단순하다. 전체 리스트에 하나의 락이 있는 것이 아니라 개별 노드마다 락을 추가하는 것이다. 리스트를 순회할 때 다음 노드의 락을 먼저 획득하고 지금 노드의 락을 해제하도록 한다.
개념적으로는, 리스트 연산에 병행성이 높아지기 때문에 괜찮은 것처럼 보인다. 하지만 실제로는 간단한 락 방법에 비해 속도 개선을 기대하기 쉽지 않다. 리스트를 순회할 때 각 노드에 락을 획득하고 해제하는 오버헤드가 매우 크기 때문이다. 아주 큰 리스트를 굉장히 많은 수의 쓰레드가 병행적으로 순회한다해도, 락을 하나만 사용하는 것보다 빠르기 어렵다. 차라리 일정 개수의 노드를 처리할 때마다 하나의 새로운 락을 획득하는 하이브리드 방법이 더 가치 있어 보인다.
병행 큐
큰 락을 사용하는 것이 병행 자료 구조를 만들기에 표준이다. 큐에서는 이 방법을 사용하지 않을 것이다.
Michael과 Scott이 설계한 조금 더 병행성이 좋은 큐가 사용하는 자료 구조와 코드는 그림 32.9에 나타나 있다.

이 코드를 보면 두 개의 락이 있는데, 하나는 큐의 헤드에, 다른 하나는 테일에 사용되는 것을 알 수 있다. 이 두 개 락의 목적은 큐에 삽입과 추출 연산에 병행성을 부여하는 것이다. 일반적인 경우에는 삽입 루틴이 테일 락을 접근하고 추출 연산이 헤드 락만을 다룬다.
Michael과 Scott은 큐 초기화 코드에 더미 노드 하나를 추가했다. 이 더미 노드는 헤드와 테일 연산을 구분하는 데 사용되었다.
큐는 멀티 쓰레드 프로그램에서 자주 사용된다. 하지만 방금 다룬 락만 있는 큐는 그런 프로그램에서 사용할 수가 없다. 큐가 비었거나 가득 찬 경우, 쓰레드가 대기하도록 하는 기능이 필요하다. 유한 큐를 만드는 법에 대해서는 조건 변수 장에서 다룰 것이다.
병행 해시 테이블
병행 자료 구조인 해시 테이블은 많이 사용된다. 동적으로 크기가 변하는 것은 그렇게 어렵지 않기에 확장이 되지 않는 간단한 해시 테이블에 집중하겠다.

이 병행 해시 테이블은 명확하다. 이전에 학습한 병행 리스트를 사용하여 구현하였으며 잘 동작한다. 성능이 우수한 이유는 전체 자료 구조에 하나의 락을 사용한 것이 아니라 해시 버켓(리스트로 구현됨)마다 락을 사용하였기 때문이다. 이렇게 하면 병행성이 좋아진다.
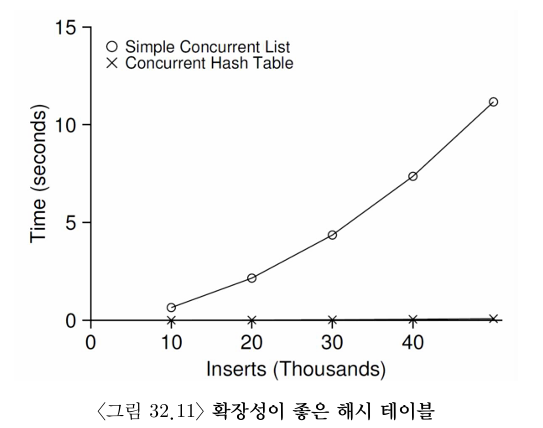
그림 32.11은 4개의 CPU를 갖는 iMac에서 4개의 쓰레드가 해시 테이블에 각각 10,000개에서 50,000개의 갱신 연산을 수행할 때의 성능을 나타낸다. 비교를 위해서 단일 락을 사용하는 연결 리스트의 성능도 함께 보였다. 그림에서 볼 수 있듯이 병행 해시 테이블은 확장성이 매우 좋은 반면, 연결 리스트는 확장성이 매우 떨어진다.
참고