[Effective C++] 6. 상속, 그리고 객체 지향 설계 [4/4]
이 글은 제 개인적인 공부를 위해 작성한 글입니다. 틀린 내용이 있을 수 있고, 피드백은 환영합니다.
항목 39 : private 상속은 심사숙고해서 구사하자
C++는 public 상속을 is-a 관계로 나타낸다. 이 점은 항목 32에서 함께 공부했다. Student가 Person으로부터 public 상속으로 파생된 상태의 클래스 계통이 주어졌을 때, 함수 호출을 성공시키기 위해 컴파일러가 Student를 Person으로 암시적 변환을 수행하는 예제를 통해 is-a 관계를 잘 설명했던 것 같다. 이 예제를 이번 항목에 다시 써먹어 보도록 하자. 대신, 상속 방식만 public 상속 말고 private 상속으로 살짝 바꾸어보겠다.
1
2
3
4
5
6
7
8
9
10
11
class Person { ... };
class Student : private Person { ... }; // 이젠 private 상속이다.
void eat(const Person& p);
void study(const Student& s);
Person p;
Student s;
eat(p); // OK
eat(s); // ERROR: Student는 Person의 일종이 아니다.
private 상속은 분명히 is-a를 뜻하지 않는다. 그렇다면 다른 뜻이 있긴 할 텐데, 무엇일까?
뜻보다 어떻게 동작하는지 먼저 알아보자. private 상속을 지배하는 첫 번째 동작 규칙은 방금 위의 예제에서 본 그대로이다. public 상속과 대조적으로, 클래스 사이의 상속 관계가 private이면 컴파일러는 일반적으로 파생 클래스의 객체를 기본 클래스의 객체로 변환하지 않는다. eat 함수 호출이 s에 대해 실패했던 이유가 바로 이것이다. 다음, 두 번째 동작 규칙은 기본 클래스로부터 물려받은 멤버는 파생 클래스에서 모조리 private 멤버가 된다는 것이다. 기본 클래스에서 원래 protected 멤버였거나 public 멤버였어도 말이다.
이제는 의미에 대해 말해보자. private 상속의 의미는 is-implemented-in-terms-of이다. B 클래스로부터 private 상속을 통해 D 클래스를 파생시킨 것은, B 클래스에서 쓸 수 있는 기능들 몇 개를 활용할 목적으로 한 행동이지, B 타입과 D 타입의 객체 사이에 어떤 개념적 관계가 있어서 한 행동은 아니라는 것이다. 단도직입적으로 말해서, private 상속은 그 자체로 구현 기법 중 하나이다. 기본 클래스로부터 물려받은 것들이 전부 파생 클래스에서 private 멤버가 되는 이유도 이것으로 설명이 된다. 기본 클래스는 그저 구현 세부사항일 뿐이란 거다. 항목 34에서 소개한 용어를 가지고 이야기하면, private 상속의 의미는 ‘구현만 물려받을 수 있고, 인터페이스는 물려받을 수 없다’라는 뜻이다. D가 B로부터 private 상속을 받으면, 이것은 그냥 D 객체가 B 객체를 써서 구현되는 거라고 생각하자. 더 바랄 것도 없다. private 상속은 소프트웨어 설계 도중에는 아무런 의미도 갖지 않으며, 단지 소프트웨어 구현(implementation) 중에만 의미를 가질 뿐이다.
그런데 private 상속의 의미가 is-implemented-in-terms-of라는 사실은 다소 헷갈리는 부분이 있기도 하다. 항목 38에서 분명 객체 합성도 똑같은 뜻을 갖는다고 했었기 때문이다. 그렇다면 이 둘(private 상속, 객체 합성) 중에 어떻게 골라야 못 골랐다는 댓글이 안 달릴까? 답은 지극히 간단하다. 할 수 있으면 객체 합성을 사용하고, 꼭 해야 하면 private 상속을 사용하자. 대체 언제가 ‘꼭 해야 하는’ 때 일까? 비공개 멤버를 접근할 때 혹은 가상 함수를 재정의할 경우가 주로 이 그림에 속한다. 비록 공간 문제가 얽히면서 완전히 private 상속으로 기울 수밖에 없는 만약의 경우도 있긴 하지만, 이 만약의 경우에 대해서는 조금 뒤에 함께 고민해 보자.
Widget 객체를 사용하는 응용 프로그램을 하나 만들고 있다고 가정하자. 무슨 바람이 불었는지는 몰라도, 어떻게 Widget 객체가 사용되는지를 좀더 이해해야 할 필요가 있다는 생각이 들었다. 다시 말해, Widget의 멤버 함수의 호출 횟수 같은 것들도 알고 싶고 실행 시간이 지남에 따라 호출 비율이 어떻게 변하는지도 알고 싶다 이거다. 실행 단계가 딱딱 구분되는 프로그램은 각 단계에 따라 보여주는 프로파일 양상도 다를 수 있다. 이를테면, 컴파일러가 소스 코드를 파싱하는 단계에서 사용된 함수들은 최적화 및 코드 생성 단계가 진행되는 동안에 사용된 함수들과 상당 부분 다른 것도 한 가지 예이다.
그런 이유로, 각 멤버 함수가 몇 번이나 호출되는지를 추적하기 위해 Widget 클래스를 직접 손보기로 한다. 멤버 함수의 호출 횟수 정보는 프로그램이 실행되는 도중에 주기적으로 점검하도록 만들 텐데, 필요하다면 이 정보 외에 각 Widget 객체의 값과 더불어 우리 생각에 유용하다고 여겨지는 다른 자료들도 넣을 수 있을 것이다. 이 작업을 위해 일종의 타이머를 하나 설치해 놓는다. 함수 사용 통계를 수집할 때를 알려주는 용도로 이 타이머를 쓰자는 것이다.
코드를 새로 만드느니 기본의 코드를 가져와 쓰는게 더 좋으므로, 예전에 만들어 두었던 유틸리티 툴킷에서 가져다 쓰자.
1
2
3
4
5
6
7
class Timer
{
public:
explicit Timer(int tickFrequency);
virtual void onTick() const;
...
};
딱 우리가 찾고 있던 것이다. Timer 객체는 반복적으로 시간을 경과시킬 주기를 우리가 정해 줄 수 있고, 일정 시간이 경과할 때마다 가상 함수를 호출하도록 되어 있다. 이 가상 함수를 재정의해서, Widget 객체의 현재 상태를 점검하면 되는 거다.
이렇게 하려면 Widget 클래스에서 Timer의 가상 함수를 재정의할 수 있어야 하므로, Widget 클래스는 어쨌든 Timer에서 상속을 받아야 한다. 하지만 지금 상황에서 public 상속은 맞지 않는다. Widget이 Timer의 일종은 아니니까. 게다가, Widget 객체의 사용자는 Widget 객체를 통해 onTick 함수를 호출해선 안 된다. 이 함수는 개념적으로 Widget 인터페이스의 일부로 볼 수 없기 때문이다. onTick 함수의 호출을 내버려 두는 것은 결국 Widget 인터페이스를 잘못 사용하기가 쉬워지게 만드는 것과 같다. ‘제대로 사용하기는 쉽게, 잘못 사용하기에는 어렵게 만들라’는 항목 18의 조언을 분명히 어기는 행동이다. public 상속은 처음부터 틀린 선택이다.
그러므로 private 상속을 하는 것이다.
1
2
3
4
5
6
class Widget : private Timer
{
private:
virtual void onTick() const override;
...
};
상속 방식을 private로 한 덕택에, Timer의 public 멤버인 onTick 함수는 Widget에서 private 멤버가 되었다. 이 함수를 직접 다시 선언한다고 해도 private 멤버인 사실은 변함이 없다. 하지만 이 onTick 함수를 public 인터페이스로 빼놓는 순간 실수의 암운이 끼기 시작할 것이다. 사용자는 분명히 ‘이 함수는 호출할 수 있구나’라고 오해할 것이고, 바로 항목 18을 위반하는 것이 되겠다.
이것만 놓고 보면 흠잡힐 게 없는 설계이다. 하지만 지금 꼭 private 상속을 할 필요가 있느냐는 점은 조금 생각해 볼 만하다. 대신에 객체 합성을 쓰기로 마음먹었다면 충분히 그렇게 해도 되는 상황이지 않는가. Timer로부터 public 상속을 받은 클래스를 Widget 안에 private 중첩 클래스로 선언해 놓고, 이 클래스에서 onTick을 재정의한 다음, 이 타입의 객체 하나를 Widget 안에 데이터 멤버로 넣는 것이다. 방금 한 이야기를 코드로 표현하면 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
class Widget
{
private:
class WidgetTimer : public Timer
{
public:
virtual void onTick() const override;
...
};
WidgetTimer timer;
...
};
private 상속만 써서 만든 설계와 비교하면 상당히 복잡한 구조이다. public 상속에다가 객체 합성까지 들어가 있고, 게다가 클래스를 새로 만들기까지 했으니까. 솔직히 말하자면, 필자가 이런 예제를 보여주는 데는 ‘하나의 설계 문제에 대한 접근 방법이 꼭 하나만 있는 것은 아니다’라는 사실과 ‘여러 가지 방법을 실제로 고민하는 습관을 들이는 것이 좋다’라는 주장을 우리에게 상기시키고 싶었던 이유가 있다. 뭐 원래 의도야 그랬지만, 현실적으로는 private 상속 대신에 public 상속에 객체 합성 조합이 더 자주 즐겨 쓰이긴 한다. 다음과 같은 두 가지 좋은 점 때문이다.
첫째, Widget 클래스를 설계하는 데 있어서 파생은 가능하게 하되, 파생 클래스에서 onTick을 재정의할 수 없도록 설계 차원에서 막고 싶을 때 유용하다. 만약에 Widget을 Timer로부터 상속시킨 구조라면 이런 게 안 된다. 심지어 상속을 private으로 해도 안 된다. 하지만 위처럼 Timer로부터 상속을 받은 WidgetTimer가 Widget 클래스의 private 영역에 있으면, Widget의 파생 클래스는 아무리 용을 써도 WidgetTimer에 접근할 수 없다. 때문에 무슨 상속을 받는다든지 가상 함수를 재정의할 만한 건덕지조차 없는 것이다.
하지만 현대 C++에서는 final 키워드가 도입되었기 때문에, 이 문제는 private 상속을 받아도 해결할 수 있다. 참고하자.
둘째, Widget의 컴파일 의존성을 최소화하고 싶을 때 좋다. Widget이 Timer에서 파생된 상태라면, Widget이 컴파일될 때 Timer의 정의도 끌어올 수 있어야 하기 때문에, Widget의 정의부 파일에서 Timer.h 같은 헤더를 포함해야 할지도 모른다. 반면, 지금의 설계에서는 WidgetTimer의 정의를 Widget으로부터 빼내고 Widget이 WidgetTimer 객체에 대한 포인터만 갖도록 만들어 두면, WidgetTimer 클래스를 간단히 선언하는 것만으로도 컴파일 의존성을 슬쩍 피할 수 있다. Timer에 관련된 어떤 것도 포함할 필요가 없으니까. 규모가 큰 시스템을 만들 때 이런 구성요소 분리는 굉장히 중요해질 수 있는 요소이다.
private 상속을 해야 할 경우에 관해서 앞에서 한 마디 늘어놓은 것을 기억할지 모르겠다. 기본 클래스의 비공개 부분에 파생 클래스가 접근해야 한다거나 가상 함수를 한 개 이상 재정의해야 할 경우가 주된 용도라고 말했었다. 이때 클래스 사이의 개념적인 관계는 is-a가 아니라 is-implemented-in-terms-of라는 점도 말했었다. 하지만 객체 합성보다 private 상속을 선호할 수밖에 없는 만약의 경우도 있다고 말했었는데, 이제 알아보자.
이 만약의 경우는 정말 ‘만에 하나’이다. 데이터가 전혀 없는 클래스를 사용할 때가 아니면 볼 수도 없다. 데이터가 없는 클래스란 비정적 데이터 멤버가 없는 클래스를 일컫는다. 그러니까 가상 함수도 없어야 하고(가상 함수가 단 한 개라도 있으면 각 객체마다 vptr이 하나씩 추가되니까. 항목 7 참조), 가상 기본 클래스도 없어야 한다(가상 기본 클래스도 크기 오버헤드를 일으키는 요인이기 때문이다. 항목 40 참조). 이런 공백 클래스(empty class) 개념적으로 차지하는 메모리 공간이 없는 게 맞다. 객체별로 저장할 데이터가 없으니 당연하다. 하지만 이런저런 기술적인 우여곡절 때문에 C++에는 “독립 구조(freestanding)의 객체는 반드시 크기가 0을 넘어야 한다”라는 이상한 금기사항 같은 것이 정해져 내려오고 있어서, 다음과 같은 코드를 써 보면
1
2
3
4
5
6
7
8
class Empty { }; // 정의할 데이터가 없으므로, 객체는 메모리를 사용하지 말아야 한다.
class HoldsAnInt // int를 저장할 공간만 필요해야 한다.
{
private:
int x;
Empty e; // 메모리 요구가 없어야 한다.
};
sizeof(HoldsAnInt) > sizeof(int)가 되는 괴현상을 목격하게 된다. Empty 타입의 데이터 멤버가 발칙하게 메모리를 요구하는 것이다. 대부분의 컴파일러에서 sizeof(Empty)의 값은 1로 나온다. 크기가 0인 독립 구조의 객체가 생기는 것을 금지하는 C++의 제약을 지키기 위해, 컴파일러는 이런 “공백” 객체에 char 한 개를 슬그머니 끼워 넣는 식으로 처리하기 때문이다. 하지만 바이트 정렬(항목 50 참조)이 필요하다고 판단되면 컴파일러는 HoldsAnInt 등의 클래스에 바이트 패딩 과정을 추가할 수도 있어서, HoldsAnInt 객체의 크기는 char 하나의 크기를 넘게 된다. 실제로는 두 번째 int를 담을 수 있는 만큼으로 늘어난다.
그런데 눈치가 빠른 독자라면, 아까부터 필자가 객체 크기가 0이면 안 된다는 이야기를 하면서 ‘독립구조’라는 말을 신경 써서 빼놓지 않은 게 수상쩍었을 것이다. 맞다. 이 C++의 제약은 파생 클래스 객체의 기본 클래스 부분에는 적용되지 않는다. 이때의 기본 클래스 부분은 독립구조 객체, 다시 말해 홀로서기를 한 객체가 아니기 때문이다. Empty 타입의 객체를 데이터 멤버로 두지 말고 Empty로부터 상속을 시켜 보면,
1
2
3
4
5
class HoldsAnInt : private Empty
{
private:
int x;
};
sizeof(HoldsAnInt) == sizeof(int)가 되는 것을 볼 수 있다. 이 공간 절약 기법은 공백 기본 클래스 최적화(empty base optimization: EBO)라고 알려져 있으며, 필자가 테스트한 모든 컴파일러에서 구현하고 있다. 메모리 공간에 무던히 신경쓰는 사용자를 상대하는 라이브러리 개발자라면 EBO를 알아두는 게 좋을 것이다. 이와 더불어 알아두면 쓸 만한 사실이 하나 더 있는데, EBO는 일반적으로 단일 상속하에서만 적용된다는 점이다. C++ 객체의 레이아웃을 결정하는 규칙이 일반적으로 이러저러한 관계로, 기본 클래스를 두 개 이상 갖는 파생 클래스에는 EBO가 적용될 수 없다고 한다.
실무적인 입장에서 이야기하면, “공백” 클래스는 진짜로 텅 빈 것이 아니다. 비정적 데이터 멤버는 안 갖고 있지만, typedef 혹은 enum, 정적 데이터 멤버는 물론이고 비가상 함수까지 갖는 경우가 비일비재하다. STL에는 방금 말한 성격의 멤버(대게 typedef 타입이다)를 포함하고 있는, 기술적으로 공백 처리된 클래스가 많이 있다. unary_function과 binary_function이 그 예인데, 이들은 사용자 정의 함수 객체를 만들 때 상속시킬 기본 클래스로 굉장히 자주 사용되는 클래스이다. 요즘은 EBO의 구현이 보편화된 덕택에, 이런 상속은 아무리 자주 되더라도 파생 클래스의 크기를 증가시키는 일이 거의 없다.
하지만 이젠 다시 ‘만약’이 아닌 일상으로 돌아올 때이다. 솔직히 말해 아무것도 없는 클래스를 사용하는 경우는 정말 드물다. 그렇기 때문에 EBO 하나만 갖고 private 상속이 뭔가 합법적으로 정당화된 것인 양 생각하는 것은 무리에 가깝다. 게다가 대부분의 상속은 is-a 관계를 나타내고, 이 부분은 public 상속이 다 맡고 있다. private 상속이 설 땅은 없다는 것이다. is-implemented-in-terms-of 관계는 객체 합성과 private 상속이 둘 다 나타낼 수 있지만, 이해하기에는 객체 합성이 훨씬 낫다. 그래서 할 수 있으면 객체 합성을 사용해야 한다고 말한 것이다.
private 상속이 적법한 설계 전략일 가능성이 가장 높은 경우가 있다. 아무리 봐 주어도 is-a 관계로 이어질 것 같지 않은 두 클래스를 사용해야 하는데, 이 둘 사이에서 한 쪽 클래스가 다른 쪽 클래스의 protected 멤버에 접근해야 하거나 다른 쪽 클래스의 가상 함수를 재정의해야 할 때가 바로 이 경우이다. 그렇다고 private 상속 아니면 안 되는 것도 아니다. 우리도 보았듯이 public 상속과 객체 합성을 적절히 잘 섞으면, 설계 복잡도는 좀더 올라가겠지만 원하는 동작을 얻을 수 있다. “private 상속을 심사숙고해서 구사하자”라는 말의 의미는, 섣불리 이것을 쓸 필요가 없다는 생각을 갖고 모든 대안을 고민한 연후에, 주어진 상황에서 두 클래스 사이의 관계를 나타낼 가장 좋은 방법이 private 상속이라는 결론이 나면 쓰라는 뜻이다.
private 상속의 의미는 is-implemented-in-terms-of(…는 …를 써서 구현됨)이다. 대개 객체 합성과 비교해서 쓰이는 분야가 많지만, 파생 클래스 쪽에서 기본 클래스의 protected 멤버에 접근해야 할 경우 혹은 상속받은 가상 함수를 재정의해야 할 경우에는 private 상속이 나름대로 의미가 있다.
객체 합성과 달리, private 상속은 공백 기본 클래스 최적화(EBO)를 활성화시킬 수 있다. 이 점은 객체 크기를 가지고 고민하는 라이브러리 개발자에게 꽤 매력적인 특징이 되기도 한다.
항목 40 : 다중 상속은 심사숙고해서 사용하자.
C++에서 다중 상속(multiple inheritance: MI)에 관한 견해를 개발자 동호회 같은 곳에서 살펴보면, 크게 두 가지 진영으로 갈리는 것을 확인할 수 있다. 한쪽 진영은 단일 상속(single inheritance: SI)이 좋다면 다중 상속은 더 좋을 것이 분명하다는 입장인 반면, 나머지 한쪽 진영에서는 단일 상속은 좋지만 다중 상속은 골칫거리밖에 안 된다고 주장한다. 우선은, MI에 관한 이 두 가지 견해가 어떤 이야기인지부터 제대로 이해하는 것을 첫 번째 목표로 잡고 공부를 시작하도록 하자.
‘다중 상속’하면 바로 우리 머리에 들어와야 하는 사실 중 하나는, 둘 이상의 기본 클래스로부터 똑같은 이름(이를테면 함수, typedef 등)을 물려받을 가능성이 생겨 버린다는 점이다. 그러니까 다중 상속 때문에도 모호성이 생긴다는 것이다. 예제를 봐 보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class BorrowableItem
{
public:
void checkOut();
...
};
class ElectronicGadget
{
private:
bool checkOut() const;
...
};
class MP3Player : public BorrowableItem, public ElectronicGadget
{
...
};
MP3Player mp;
mp.checkOut(); // 모호성 발생! 어느 checkOut인지 알 수 없다.
잘 보자. checkOut 함수를 호출하는 부분에서 모호성이 발생하고 있는데, 여기서 눈여겨둘 사실은 두 checkOut 함수들 중에서 파생 클래스가 접근할 수 있는 함수가 딱 결정되는 것이 분명한데도 모호성이 생긴다는 점이다. 이것은 중복된 함수 호출 중 하나를 골라내는 C++의 규칙을 따른 결과이다. 어떤 함수가 접근 가능한 함수인지를 알아 보기 전에, C++ 컴파일러는 이 규칙을 써서 주어진 호출에 대해 최적으로 일치하는 함수인지를 먼저 확인한다. 다시 말해, 최적 일치 함수를 찾은 후에 비로소 함수의 접근가능성을 점검한다는 이야기이다. 지금의 경우 두 checkOut 함수는 C++ 규칙에 의한 일치도가 서로 같기 때문에, 최적 일치 함수가 결정되지 않는다. 그렇기 때문에 ElectronicGadget::checkOut 함수의 접근가능성이 점검되는 순서조차 오지 않는 것이다.
이 모호성을 해소하려면, 호출할 기본 클래스의 함수를 우리가 손수 지정해 주어야 한다.
1
mp.BorrowableItem::checkOut();
물론 ElectronicGadget::checkout 함수를 호출해 보려는 사람도 있겠지만, 함수 호출 모호성 에러가 나올 자리에 private 멤버 함수를 호출하려는 컴파일 에러가 나올 뿐이다.
다중 상속의 의미는 그냥 ‘둘 이상의 클래스로부터 상속을 받는 것’일 뿐이지만, 이 MI는 상위 단계의 기본 클래스를 여러 개 갖는 클래스 계통에서 심심치 않게 눈에 띈다. 이런 구조의 계통에서는 소위 “죽음의 MI 마름모꼴(deadly MI diamond)”이라고 알려진 좋지 않은 모양이 나올 수 있다.
1
2
3
4
class File { ... };
class InputFile : public File { ... };
class OutputFile : public File { ... };
class IOFile : public InputFile, public OutputFile { ... };
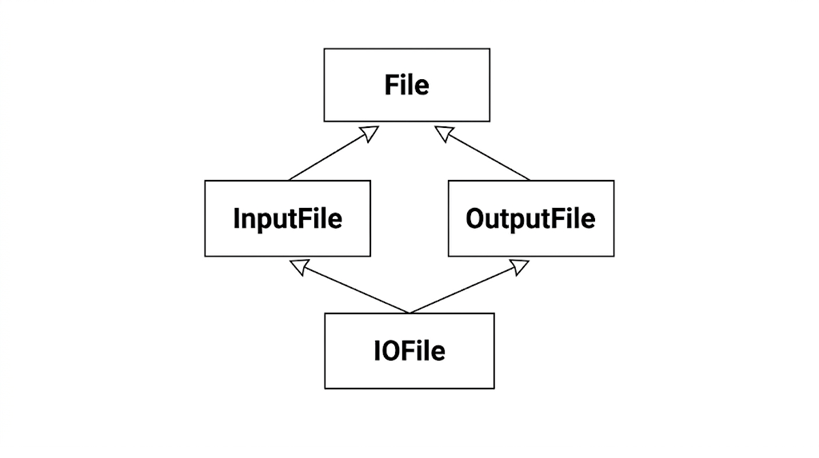
이렇게 기본 클래스와 파생 클래스 사이의 경로가 두 개 이상 되는 상속 계통을 혹시라도 쓰게 되면, 언제라도 우리는 “기본 클래스의 데이터 멤버가 경로 개수만큼 중복 생성되는 것인데, 진짜 알고 그랬어?”라는 의혹을 피해 가지 못하게 된다. 예를 들어, File 클래스 안에 fileName이라는 데이터 멤버가 하나 들어 있다고 생각해 보자. IOFile 클래스에는 이 필드가 몇 개가 들어 있어야 할까? 바로 위의 기본 클래스로부터 사본을 하나씩 물려받게 되니까 결과적으로 fileName 데이터 멤버가 두 개이어야 할 것도 같다. 한편으로는 단순한 논리로 보아 IOFile 객체는 파일 이름이 하나만 있는게 맞으니까, 두 기본 클래스로부터 fileName을 동시에 물려받더라도 fileName이 중복되면 안 될 것도 같다.
C++는 이 논란에서 어떤 입장도 취하지 않는다. 아주 태평하게 두 가지를 모두 지원한다. 기본적으로는 데이터 멤버를 중복생성하는 쪽이지만 말이다. 만약 데이터 멤버의 중복 생성을 원한 것이 아니었다면, 해당 데이터 멤버를 가진 클래스(File)를 가상 기본 클래스(virtual base class)로 만드는 것으로 해결을 볼 수 있다. 더 자세히 말하자면, 가상 기본 클래스로 삼을 클래스에 직접 연결된 파생 클래스에서 가상 상속(virtual inheritance)을 사용하게 만드는 것이다. 이렇게 말이다.
1
2
3
4
class File { ... };
class InputFile : virtual public File { ... };
class OutputFile : virtual public File { ... };
class IOFile : public InputFile, public OutputFile { ... };
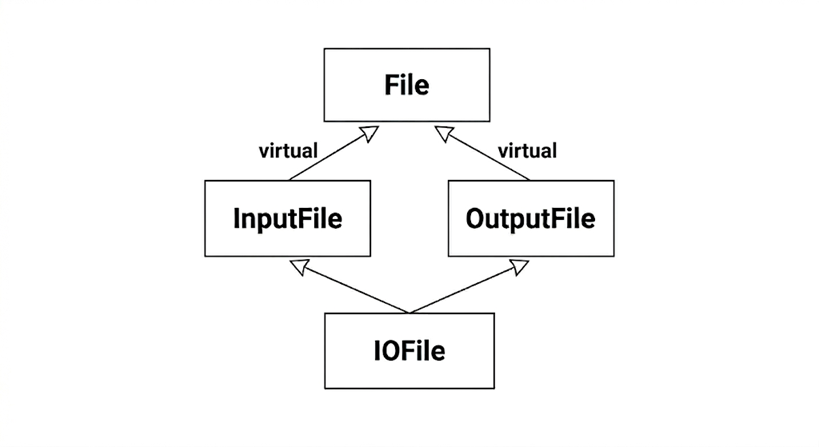
사실 표준 C++ 라이브러리가 이런 모양의 MI 상속 계통을 하나 갖고 있다. 클래스가 아니라 클래스 템플릿이라는 것이 예외이다. 이름은 basic_ios, basic_istream, basic_ostream, basic_iostream이다. 위의 File, InputFile, OutputFile, IOFile 자리에 하나씩 들어가면 된다.
정확한 동작의 관점에서 보면, public 상속은 항상 가상 상속이어야 하는 것이 맞다. 만약에 관점이 이것밖에 없었더라면 이야기는 무척 단순해진다. “public 상속을 하려거든 반드시 가상 public 상속으로 할 것”이란 규칙만 외우면 된다. 하지만 우리는 정확성 외에 다른 측면도 같이 생각할 수밖에 없다. 사실, 상속되는 데이터 멤버의 중복생성을 막는 데는 우리 눈에는 보이지 않는 컴파일러의 숨은 꼼수가 필요하다. 그리고 그 꼼수 덕택에, 가상 상속을 사용하는 클래스로 만들어진 객체는 가상 상속을 쓰지 않은 것보다 일반적으로 크기가 더 크다. 게다가, 가상 기본 클래스의 데이터 멤버에 접근하는 속도도 비가상 기본 클래스의 데이터 멤버에 접근하는 속도보다 느리다. 세부적인 크기/속도 차이는 컴파일러마다 다르지만, 어쨌든 이 점만은 분명히 말할 수 있다. 가상 상속은 비싸다.
이것으로 비용 지불을 끝냈으면 좋겠지만, 다른 쪽으로 또 비용이 나간다. 가상 기본 클래스의 초기화에 관련된 규칙은 비가상 기본 클래스의 초기화 규칙보다 훨씬 복잡한데다가 직관성도 떨어진다. 대부분의 경우, 가상 상속이 되어 있는 클래스 계통에서는 파생 클래스들로 인해 가상 기본 클래스 부분을 초기화할 일이 생기게 된다. 이때 들어가는 초기화 규칙은 다음과 같다.
- 초기화가 필요한 가상 기본 클래스로부터 클래스가 파생된 경우, 이 파생 클래스는 가상 기본 클래스와의 거리에 상관없이 가상 기본 클래스의 존재를 염두에 두고 있어야 한다.
- 기존의 클래스 계통에 파생 클래스를 새로 추가할 때도 그 파생 클래스는 가상 기본 클래스(역시 거리에 상관없이)의 초기화를 떠맡아야 한다.
가상 기본 클래스(가상 상속)에 대해서 드릴 수 있는 조언은 간단하다. 첫째, 구태여 쓸 필요가 없으면 가상 기본 클래스를 사용하지 말자. 비가상 상속을 기본으로 삼으라 이거다. 둘째, 가상 기본 클래스를 정말 쓰지 않으면 안 될 상황이라면, 가상 기본 클래스에는 데이터를 최대한 넣지 않는 쪽으로 신경쓰자. 데이터만 들어가지 않으면 가상 기본 클래스의 초기화 규칙(곧 알겠지만 대입도 포함)만 생각하면 떠오르는 복잡도가 훨씬 줄어들 것이다. 참고로, C++의 가상 기본 클래스와 여러가지 측면에서 비교가 되는 것이 자바와 닷넷의 interface라는 개념인데, 자바와 닷넷의 인터페이스는 언어적으로 데이터를 아예 갖지 못하도록 정해져있다.
자, 이번에는 C++ 인터페이스 클래스를 써서 사람을 모형화해 보도록 하자.(항목 31 비슷하다)
1
2
3
4
5
6
7
8
class IPerson
{
public:
virtual ~IPerson();
virtual std::string name() const = 0;
virtual std::string birthDate() const = 0;
};
IPerson을 쓰려면 분명히 IPerson 포인터 및 참조자를 통해 프로그래밍을 해야 할 것이다. 추상 클래스를 인터페이스로 만들 수는 없으니까. 조작이 가능한 IPerson 객체를 생성하기 위해, IPerson의 사용자는 팩토리 함수를 사용해서 IPerson의 구체 파생 클래스를 인스턴스로 만든다.
1
2
3
4
5
6
7
std::shared_ptr<IPerson> makePerson(DatabaseID personIdentifier);
DatabaseID askUserForDatabaseID();
DatabaseID id(askUserForDatabaseID());
std::shared_ptr<IPerson> pp(makePerson(id));
그런데 makePerson 함수는 어떻게 해서 그 함수가 반환할 포인터를 객체로 새로 만들 수 있는 것일까? 모르긴 해도, 분명히 makePerson 함수가 인스턴스로 만들 수 있는 구체 클래스가 IPerson으로부터 파생되어 있어야 할 것이다.
이 클래스의 이름이 CPerson이라고 가정하자. 구체 클래스가 원래 그렇듯, CPerson은 IPerson으로부터 물려받은 순수 가상 함수에 대한 구현을 제공해야 한다. 물려받은 것은 껍데기뿐이니 어쨌든 바닥부터 구현할 수도 있겠지만, 남이 만들었거나 자기가 만들어 둔 코드를 이리 맞추고 저리 맞추는 게 더 나을지도 모르겠다. 이를테면, 꽤 오래 됐긴 했지만 예전에 준비해 둔 데이터베이스 전담 클래스인 PersonInfo를 보니 현재의 CPerson에 필요한 핵심 기능을 다 갖고 있었다는 가정을 세워봅시다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class PersonInfo
{
public:
explicit PersonInfo(DatabaseID pid);
virtual ~PersonInfo();
virtual const char* theName() const;
virtual const char* theBirthDate() const;
...
private:
virtual const char* valueDelimOpen() const;
virtual const char* valueDelimClose() const;
...
};
멤버 함수의 반환 타입을 보니 요즘처럼 string 객체를 반환하는 것이 아니라 const char*를 반환하고 있다.
PersonInfo 클래스를 이리저리 살피다가, 이 클래스에는 데이터베이스 필드를 다양한 서식으로 출력할 수 있는 기능을 갖고 있다는 사실을 알아냈다. 이 기능을 쓰면 각 필드 값의 시작과 끝을 임의의 문자열로 구분하여 출력할 수 있다. 기본적으로, 출력용 필드 값의 시작과 끝에 붙는 구분자가 대괄호로 미리 정해져 있다. 그러니까 어떤 필드 값이 “Ring-tailed Lemur”이라면 ‘[Ring-tailed Lemur]’라는 식으로 출력된다는 것이다.
PersonInfo의 사용자가 전부 대괄호를 구분자로 쓰고 싶어하지는 않을 것이라는 점은 대부분 알고 있으므로, 사용자가 원하는 시작 구분자와 끝 구분자를 파생 클래스에서 지정할 수 있도록 valueDelimOpen과 valueDelimClose 함수를 가상 함수로 마련해 두자. 그리고 PersonInfo 클래스의 다른 멤버 함수들은 이 가상 함수를 통해 자신들이 사용하는 필드 값에 적절한 구분자를 붙이도록 구현되는 것이다. PersonInfo::theName 함수를 에로 들면 다음과 같이 코드가 나올 것이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
const char* PersonInfo::valueDelimOpen() const
{
return "[";
}
const char* PersonInfo::valueDelimClose() const
{
return "]";
}
const char* PersonInfo::theName() const
{
// 반환 값을 위한 버퍼를 예약. 이 버퍼는 정적 메모리이기 때문에, 자동으로 모두 0으로 초기화된다.
static char value[Max_Formatted_Field_Value_Length];
// 시작 구분자를 value에 쓴다.
std::strcpy(value, valueDelimOpen());
// value에 들어 있는 문자열에 이 객체의 name 필드를 덧붙인다. 버퍼 오버런이 일어나지 않도록 주의
// 끝 구분자를 value에 추가.
std::strcat(value, valueDelimClose());
return value;
}
이런 구시대적인 스타일로 설계된 함수를 써야 하는지 이해가 안 될 수도 있지만, (특히 정적 버퍼를 쓰는 부분은 버퍼 오버런은 물론이고 스레딩 문제까지 동시에 일으킬 수 있다. 항목 21을 함께 읽어보자.) 그런 불만은 잠시 접어두고 이 부분에만 집중하자. theName은 valueDelimOpen을 호출해서 시작 구분자를 만들고, name 값 자체를 만든 다음, valueDelimClose를 호출하도록 구현됐다는 점 말이다. 이때 valueDelimOpen 및 valueDelimClose는 가상 함수이기 때문에, theName이 반환하는 결과는 PersonInfo에만 좌우되는 것이 아니라 PersonInfo로부터 파생된 클래스에도 좌우된다.
CPerson을 구현하는 사람의 입장에서 볼 때 이 점은 아주 반가운 소식이다. 그도 그럴것이, 이런 내용이 적힌 IPerson의 문서를 읽다 보면 name과 birthDate 함수가 반환하는 값에는 장식, 즉 구분자가 붙으면 안 된다는 사실을 알게 될 테니까이다. 어떤 사람의 이름이 Homer라면 그 사람의 name 함수는 “[Homer]”이 아니라 “Homer”를 반환해야 한다는 것이다.
CPerson과 PersonInfo 사이를 잇는 관계고리는 별 거 없다. PersonInfo 클래스는 CPerson을 구현하기 편하게 만들어 주는 함수를 어쩌다가 갖고 있다는 것이다. 사실 이게 전부이다. 앞 항목에서 배운 유식한 말로 대신하면 “is-implemented-in-terms-of” 관계이다. 알겠지만 이 관계를 표현하는 방법은 객체 합성과 private 상속, 이렇게 두 가지가 있다. 항목 39에서 지적했듯이 대부분의 경우에 선호하는 방법은 객체 합성이지만, 가상 함수를 꼭 정의해야 한다면 private 상속을 써야 한다. 자, 지금의 경우는 뭐가 좋을까? CPerson 클래스에서는 valueDelimOpen과 valueDelimClose를 반드시 재정의해야 하므로, 단순한 객체 합성으로는 목적 달성이 불가능하다. 현재 머리를 굴려서 찾을 수 있는 가장 평이한 해결책은 CPerson이 PersonInfo로부터 private 상속을 받도록 만드는 것이다. 뭐, 약간의 수고가 들어가긴 하지만 객체 합성과 public 상속을 조합하는 방법으로도 PersonInfo의 가상 함수를 효과적으로 재정의할 수 있다. 여기서는 private 상속을 이용해 보자.
한편, CPerson 클래스는 IPerson 인터페이스도 함께 구현하지 않으면 안 되기 때문에, 이를 위해 public 상속이 필요하다. 가만가만, 이렇게 해 놓고 보니 다중 상속을 의미 있게 써먹는 예가 하나 생긴다. 바로 지금처럼 인터페이스의 public 상속과 구현의 private 상속을 조합하는 것 말이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
class IPerson
{
public:
virtual ~IPerson();
virtual std::string name() const = 0;
virtual std::string birthDate() const = 0;
};
class DatabaseID { ... };
class PersonInfo
{
public:
explicit PersonInfo(DatabaseID pid);
virtual ~PersonInfo();
virtual const char* theName() const;
virtual const char* theBirthDate() const;
virtual const char* valueDelimOpen() const;
virtual const char* valueDelimClose() const;
...
};
class CPerson : public IPerson, private PersonInfo // MI가 쓰인다.
{
public:
explicit CPerson(DatabaseID pid) : PersonInfo(pid) { }
virtual std::string name() const
{ return PersonInfo::theName(); }
virtual std::string birthDate() const
{ return PersonInfo::theBirthDate(); }
private:
const char* valueDelimOpen() const
{ return ""; }
const char* valueDelimClose() const
{ return ""; }
};
이번 예제를 보면, MI도 경우에 따라서는 상당히 쓸 만하고 나름대로 의미가 있다는 사실을 알 수 있을 것이다.
슬슬 이야기를 접을 때가 됐다. 다중 상속은 대단한 게 아니다. 그냥 객체 지향 기법으로 소프트웨어를 개발하는 데 쓰이는 도구 중 하나로 보자. 단일 상속과 비교해서 사용하기에도 좀더 복잡하고 이해하기에도 좀더 복잡하다는 것은 사실이므로, MI 설계와 동등한 효과를 내는 SI 설계를 뽑을 수 있다면 SI 쪽으로 가는 것이 확실히 좋다. 머리에 쥐가 나게 궁리해서 MI 설계밖에 나오지 않는다 해도 조금만 더 힘내자. 웬만한 경우엔 SI로도 똑같이 할 수 있는 방법을 찾을 수 있다. 물론, 가장 명료하고 유지보수성도 가장 좋으며 가장 적합한 방법이 MI일 경우도 진짜로 존재한다. ‘이때다’라고 확신이 들면 주저 말고 MI를 지르는 거다. 다중 상속을 쓸 때 혹시라도 성급하지는 않았나, 확인하고 또 확인하라는 말이다.
다중 상속은 단일 상속보다 확실히 복잡하다. 새로운 모호성 문제를 일으킬 뿐만 아니라 가상 상속이 필요해질 수도 있다.
가상 상속을 쓰면 크기 비용, 속도 비용이 늘어나며, 초기화 및 대입 연산의 복잡도가 커진다. 따라서 가상 기본 클래스에는 데이터를 두지 않는 것이 현실적으로 가장 실용적이다.
다중 상속을 적법하게 쓸 수 있는 경우가 있다. 여러 시나리오 중 하나는, 인터페이스 클래스로부터 public 상속을 시킴과 동시에 구현을 돕는 클래스로부터 private 상속을 시키는 것이다.
추가로,
[[no_unique_address]] 속성
C++ 20부터 [[no_unique_address]] 속성이 도입되었다. 이 속성은 이 데이터 멤버가 해당 클래스의 다른 비정적 데이터 멤버나 기본 클래스의 하위 객체와 중첩될 수 있도록 한다는 의미이다. Empty Class를 멤버 변수로 가지고 있어도 크기에 포함되지 않는다 책에서 설명한 EBO와 결과가 같은 것을 볼 수 있다. 따라서 EBO 목적을 위해 private 상속을 쓸 필요가 없다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <iostream>
class Empty {};
class TestClass {
[[no_unique_address]] Empty e;
int data;
};
int main() {
TestClass tc;
std::cout << sizeof(TestClass) << std::endl; // 4 byte
std::cout << &tc.e << std::endl; // 동일한 주소
std::cout << &tc.data << std::endl; // 동일한 주소
return 0;
}
CRTP(Curiously Recurring Template Pattern)
CRTP는 파생 클래스가 기본 클래스의 템플릿 인자로 자기 자신을 넘기는 패턴이다. 기존 상속에서는 부모가 자식이 누구인지 모르기 때문에 런타임에 동적 바인딩(가상 함수 호출)을 해야 했다. 하지만 CRTP는 컴파일 타임에 부모가 자식의 타입을 알 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// 부모 클래스가 템플릿 인자로 자식의 타입을 받음
template <typename Derived>
class Serializable
{
public:
void serialize()
{
// 컴파일 타임에 자식 타입으로 정적 캐스팅
auto* derived = static_cast<Derived*>(this);
// 자식 클래스에 있는 기능을 가상 함수 없이 직접 호출
std::cout << "값 출력: " << derived->getName() << "\n";
}
};
// 자식 클래스는 부모를 상속받을 때 자기 자신을 주입
class Widget : public Serializable<Widget>
{
public:
std::string getName() const { return "Widget"; }
};
CRTP는 가상 함수가 없기에, 객체 내부에 vptr(가상 함수 포인터)가 생성되지 않아, 메모리가 절약되고 런타임 오버헤드 없이 일반 함수 호출처럼 동작한다.
참고